目录
总结
1、回归算法-线性回归分析
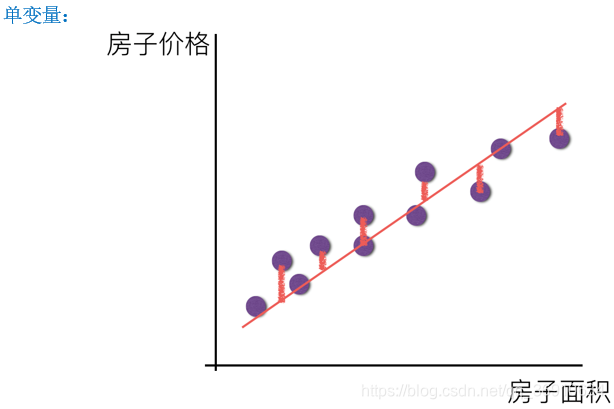
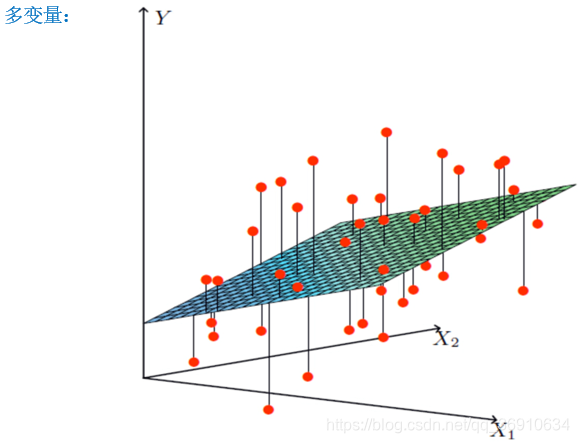
线性模型

线性回归

自变量:特征值 因变量:目标值
损失函数(误差大小)

如何去求模型当中的W,使得损失最小?
(目的是找到最小损失对应的W值)
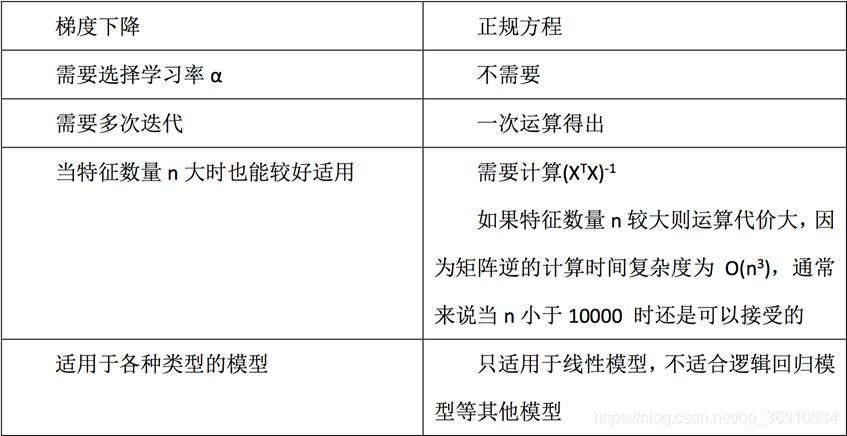
最小二乘法之正规方程(不做要求)
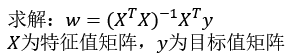
缺点:当特征过于复杂,求解速度太慢
对于复杂的算法,不能使用正规方程求解(逻辑回归等)
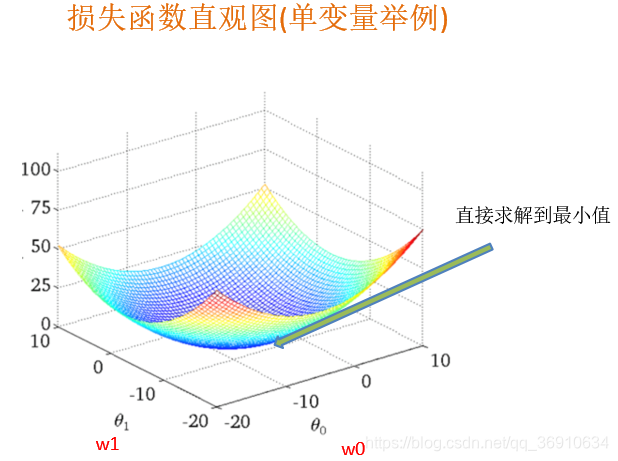
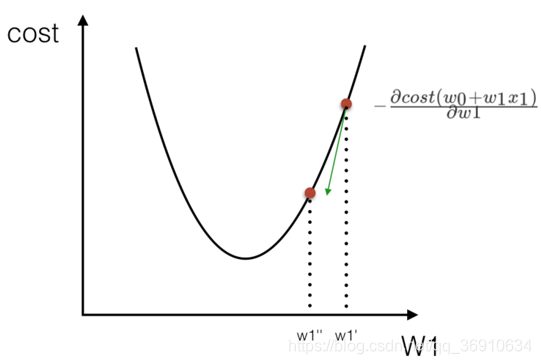
最小二乘法之梯度下降(理解过程)

向损失最小的方向,找损失最小的时候
sklearn线性回归正规方程、梯度下降API
•sklearn.linear_model.LinearRegression
•正规方程
•sklearn.linear_model.SGDRegressor
•梯度下降
LinearRegression、SGDRegressor
•sklearn.linear_model.LinearRegression()
•普通最小二乘线性回归
•coef_:回归系数
•sklearn.linear_model.SGDRegressor( )
•通过使用SGD最小化线性模型
•coef_:回归系数
2、线性回归实例
波士顿房价数据案例分析流程
1、波士顿地区房价数据获取
2、波士顿地区房价数据分割
3、训练与测试数据标准化处理
4、使用最简单的线性回归模型LinearRegression和梯度下降估计SGDRegressor对房价进行预测
3、回归性能评估

sklearn回归评估API
•sklearn.metrics.mean_squared_error
mean_squared_error
•mean_squared_error(y_true, y_pred)
•均方误差回归损失
•y_true:真实值
•y_pred:预测值
•return:浮点数结果
注:真实值,预测值为标准化之前的值
1、LinearRegression与SGDRegressor评估
2、特点:线性回归器是最为简单、易用的回归模型。
从某种程度上限制了使用,尽管如此,在不知道特征之间关系的前提下,我们仍然使用线性回归器作为大多数系统的首要选择。
小规模数据:LinearRegression(不能解决拟合问题)以及其它
大规模数据:SGDRegressor
过拟合与欠拟合
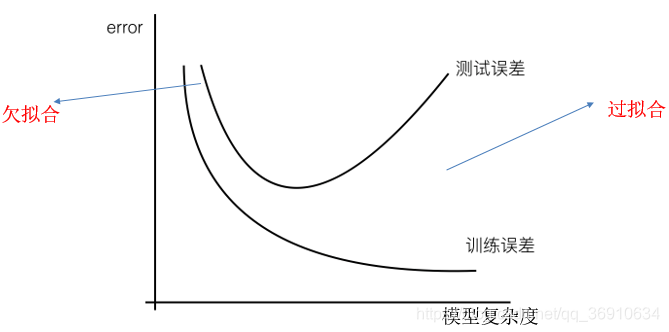
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获得更好的拟合, 在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
欠拟合原因以及解决办法
•原因:
•学习到数据的特征过少
•解决办法:
•增加数据的特征数量
过拟合原因以及解决办法
•原因:
•原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
•解决办法:
•进行特征选择,消除关联性大的特征(很难做)
•交叉验证(让所有数据都有过训练)
•正则化(了解)
L2正则化
作用:可以使得W的每个元素都很小,都接近于0
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
带有正则化的线性回归-Ridge
•sklearn.linear_model.Ridge
Ridge
•sklearn.linear_model.Ridge(alpha=1.0)
•具有l2正则化的线性最小二乘法
•alpha:正则化力度
•coef_:回归系数
线性回归 LinearRegression与Ridge对比
•岭回归:回归得到的回归系数更符合实际,更可靠。另外,能让估计参数的波动范围变小,变的更稳定。在存在病态数据偏多的研究中有较大的实用价值。
sklearn模型的保持和加载
![]()
保存和加载API

4、分类算法-逻辑回归
逻辑回归是解决二分类问题的利器
逻辑回归
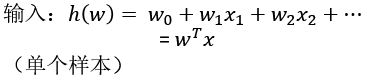
sigmoid函数
逻辑回归公式

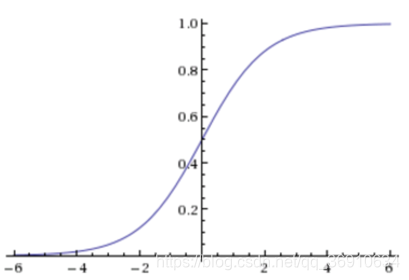
逻辑回归的损失函数、优化(了解)


sklearn逻辑回归API
•sklearn.linear_model.LogisticRegression
LogisticRegression
•sklearn.linear_model.LogisticRegression(penalty=‘l2’, C = 1.0)
•Logistic回归分类器
•coef_:回归系数
LogisticRegression总结
应用:广告点击率预测、电商购物搭配推荐
优点:适合需要得到一个分类概率的场景
缺点:当特征空间很大时,逻辑回归的性能不是很好
(看硬件能力)
5、聚类算法-kmeans
非监督学习(unsupervised learning)
主要方法:k-means
k-means步骤

k-means API
•sklearn.cluster.KMeans
Kmeans
•sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
•k-means聚类
•n_clusters:开始的聚类中心数量
•init:初始化方法,默认为'k-means ++’
•labels_:默认标记的类型,可以和真实值比较(不是值比较)
k-means对Instacart Market用户聚类
1、降维之后的数据
2、k-means聚类
3、聚类结果显示
Kmeans性能评估指标
